Project List
01219116 Programming II
Second Semester, 2022. Section 450
Laptops Analysis
Description
This project is designed to analyze data on each laptop brands, models etc. visualize it using graphs such as Histogram, Boxplot, Pie chart Bar graph and provide detailed information to help users make informed decisions when purchasing a laptop.
Data Sources
My database for this application from Kaggle.com Laptop Specs and latest price | Kaggle
Running the Application
Any python text editor and go to main.py and run it
Design
Class describe
- Reader class: Was created for the purpose of the CSV file and changed to Pandas DataFrame, including basic data cleaning.
- Analysis class: Was created for the purpose of working backend behind the calculation system by PandasDataFrame. Include creating a graph before being presented in the frontend system.
- GuiTools: Was created to make the Class GUI work easier, such as creating a repeated window TopLevel template and Combobox
- GUI: Was built to bring the information that has been processed and presented with GUI (Tkinter)
Other Information
Used module - tkinter - tkinter.ttk - pandas - pandastable - matplotlib.backends.backend_tkagg - networkx

This project will mimic a food ordering/delivery application. The user can choose a variety of Indian food. Or filter out and left only prefered menus, for example, choosing only spicy food, or choosing only vegan food, or maybe selecting only the desserts.

This application illustrates the bar charts for comparing the ratio datas between two user-defined NASA Astronauts, and the histogram for displaying Astronaut amounts for each selected property. Furthermore, the users can select the Descriptive statistics that classified by group to analyze the numerical information of the selected NASA astronaut in the bar chart

Pharmalyst
Description
Pharmalyst is a medication store using python tkinter to build GUI.
The Project uses medication dataset to provide an information about the medication such as medication name, description of the medication, category of that medication and quantity. The system can load and generate based on specific customer purchased history.
Pharmalyst are also include the authentication system, allowing an admin to see the current statistics of the store, normal customer can browse through all of the medication category that they want to.
To start the program you will have to install all of the necessary dependencies then run the file named "Monitor.py"
Data Sources
All of the medication dataset are from Kaggle - Medication dataset This dataset provided name and description of the medication that I used in this project.
Dependencies
Here's are the list of necessary dependencies that I used in the project.
-
tkinter
-
Pillow
-
networkx
-
numpy
-
pandas
-
matplotlib
You can install these dependencies by this command.
pip install -r requirements.txt
Diagrams
For both sequence and UML diagrams you can view both from via this link
Design Patterns Used
In this project I used facade design pattern as a way to simplify the interface between "Monitor" class and the rest of the class in the lower layer. Facade act like a medium and lower interaction between representation layered and domain layer. This helps reduce the complexity of the code and make it easier to maintain.
Graph Algorithm Used
My project is to build a medication store, the features that use graph problems to solve would be the recommendation engine. I want to create recommendations based on the purchase history of that specific customer.
The Idea is to find shortest path from given vertex to all other vertices and then counting the number of vertices that are reachable, The key idea is that if a medication category is more popular, then more medications in that category will be ordered by customers, and hence more nodes will be reachable from the node representing that category.

ANIME SENSEI
Description
AnimeSensei is an application designed to explore and analyze anime data using graph analysis techniques. By leveraging the power of graphs, the application provides insights into various aspects of anime, such as release trends, episode counts, ratings, and related tags. This article will delve into the details of the application's functionality, data sources, design, graph algorithm used, and other interesting aspects.
Data Sources
I use Anime-3.csv and this is sources from kaggle https://www.kaggle.com/code/kishan9044/anime-recommender
Running the Application
To run the AnimeSensei application, ensure that the required dependencies are installed. These dependencies include libraries such as Matplotlib, Pandas, NetworkX, spicy and Tkinter. Once the dependencies are set up, execute the application script, and the main window of AnimeSensei will open. From there, users can navigate through various features and explore the anime data.
Design
The application follows a graphical user interface (GUI) design using the Tkinter library. It consists of three main frames: the ANIMESENSEI header frame, the Home, Statistic, Quit frame for navigation, and the Display Graph frame for visualizations. Each frame contains buttons that allow users to interact with different functionalities of the application.
To provide a seamless user experience, the application utilizes the MyAnimeData class, which encapsulates data retrieval, preprocessing, and graph-related operations. This class acts as a bridge between the GUI and the underlying data.
Design Patterns Used
In AnimeSensei, the Facade pattern is employed to create the MyAnimeData class, which acts as the facade for interacting with the anime dataset and performing various operations. The MyAnimeData class encapsulates the complexity of data retrieval, preprocessing, and graph-related functionalities, providing a simple and intuitive interface for users.
Graph Algorithm Used
One of the key features of AnimeSensei is the graph analysis capability. Specifically, the application employs Breadth-First Search (BFS) algorithm to solve the problem of exploring related anime based on tags. By constructing a graph representation of the anime data, BFS enables users to discover anime series that share common tags, facilitating the exploration of similar shows
Other Information
Throughout the development of AnimeSensei, several interesting libraries and packages were utilized. Matplotlib provides robust charting and visualization capabilities, enabling the creation of appealing graphs and charts. Pandas, on the other hand, offers powerful data manipulation and analysis tools, allowing efficient preprocessing and exploration of the anime dataset.
Additionally, the NetworkX library proved instrumental in constructing and analyzing graphs. It offers a comprehensive set of graph algorithms and data structures, simplifying the implementation of graph-related functionalities within the application.
Here is my class diagram

Here is my sequence diagram


This project aims to analyze a dataset containing songs of various artists around the world. The dataset includes statistics of each song's music version on Spotify, such as the number of streams, and the number of views of the official music video on YouTube.
GitHub: https://github.com/SirisilpK/year-project-thanidacwn

Description
this program was create to analysis data of the nice place for working and visualize it with Histogram, scatter plot and network graph to help user decisions for the country to go next.
Data Sources
my data from Kaggle name The Best Cities for a Workation.
Running the Application
I used 5 package (1) pillow v.9.5.0 (2) tkinter (3) pandas v.2.8.2 (4) matplotlib v.3.7.1 (5) networkx v.3.1
Class Describe
- Menu: this class contain option menu and presented with tkinter.
- Scatter: this class create scatter plot form selecting data by user.
- Require_graph this class will show distribution and scatter plot of fix data.
- Network_graph this class will create net work graph.
- Read_file this class will read data from csv file.

This application allows users to analyze video game sales data from 1980 to 2020. Please select the desired values from the provided comboboxes and click the "Graph" button to generate and visualize the corresponding graph. Please note that there may be missing data for certain years as the data source may not have records for those years.

SpotiViz
Project description and features
SpotiViz is a Python program that uses "Top 100 Most Streamed Songs on Spotify" to retrieve and analyze track information, including audio features such as danceability, energy, and loudness. The program provides a GUI interface that allows users to search for tracks by artist, album, or track name, and select specific tracks to analyze. Users can also select which audio features to visualize and analyze, such as beats.per.minute, energy or danceability. The processed data is then displayed using various charts and graphs, such as scatter plots, histograms, and bar charts, to display the audio features of each track.
The project will be implemented using Python, with the following main components:
-
Data Loading and Processing: The dataset will be loaded into a Python data structure (e.g., Pandas dataframe) and processed to extract relevant features and information.
-
Graphical User Interface (GUI): A GUI will be developed using the Tkinter library to provide an interactive interface for users to explore the dataset. The GUI will allow users to select and filter data based on different criteria (e.g., artist, energy, danceability), and display visualizations of the data.
-
Data Visualization: The processed data will be visualized using various graphical representations, such as bar charts, scatterplots, and network graphs. These visualizations will provide insights into the most popular songs and artists, as well as user listening behavior and preferences.
Data sources
"Top 100 Most Streamed Songs on Spotify" from https://www.kaggle.com/datasets/pavan9065/top-100-most-streamed-songs-on-spotify
Running the application, including libraries used and installation
Tkinter: a standard Python GUI library used for creating and managing windows, buttons, labels, etc. in the user interface.
Matplotlib: a popular data visualization library in Python used for creating various types of charts and graphs.
Random: a module that provides functions for generating random numbers and data.
Numpy: a library for numerical computing in Python. It provides functions for working with arrays, matrices, and other numerical data types.
Pandas: for data frame and data visualization.
Networkx: a library for working with graphs and networks in Python. It provides functions for creating, manipulating, and analyzing graphs, including algorithms for shortest.
Sklearn: a library for machine learning in Python. It provides functions for clustering, regression, classification, and other machine learning tasks.
Requirements
- Python 3.x installed on the system.
- virtual env
pip install virtualenv
How to run code in terminal
cd SpotiVizProgram
python main.py
Or you can install by requirement.txt
Design patterns used
- Facade - MVC (Model-View-Controller) pattern: Using this pattern helps to divide the program into clear and distinct parts, making it easier to manage the program.
Graph problem modeling and algorithm
- I use the shortest-path algorithm to recommend songs. The program will recommend 5 songs that are similar to the selected target song. There will be two recommendation functions in the program that use this algorithm, with one using the sklearn library to speed up the process.

FIFA 22 Data Analysis
Description
The application represents the distribution of the data which I would like to represent and personally think it's interesting, time series line graph and the descriptive statistic of each distribution
Data Sources
FIFA 22 complete player dataset from Kaggle.
here is a link: (https://www.kaggle.com/datasets/stefanoleone992/fifa-22-complete-player-dataset)
Running the Application
Users can run the application in main.py
Package: pandas, matplotlib, tkinter and numpy
Design
There are 3 classes for the application. Application,
FIFA22playerData and FacadeController

For this project, I will be using the World Happiness Report dataset from Kaggle, which contains data from 2015 on various factors that contribute to overall happiness scores in different countries. The goal of the project is to create an interactive application that allows users to explore and analyze the data in different ways. The application will have several features, including the ability to filter and sort the data based on different variables such as country, year, and happiness score. The processed data will be visualized using a variety of charts and graphs to help users understand patterns and trends in the data. For example, user can plotting the bar graph to see the differentation of the attribute for each country, and also user can switch to plot a bar chart or a network graph. The user interface will be designed to be intuitive and easy to use, with clear instructions and explanations of the data and processing options. The application will be accessible to a wide range of users, including researchers, policymakers, and anyone interested in exploring the factors that contribute to happiness around the world.

Harry Potter Movies
Description
The Harry Potter is a collection of various types of data related to the popular book and movie series. A Harry Potter data set project is an exciting opportunity to delve into the intricacies of the Wizarding World. The project involves cleaning and preparing data related to the characters, spells, potions, budget, and box office revenue for each part of the series.
Data Sources
The data is collected from the following sources:
Running the Application
- Install the dependencies using the following command:
requests
io
pandas
matplotlib
Pillow
- Run the application using the following command:
main.py
Design

From the above diagram, the following classes are used:
-
FacadeController
-
hp_data
-
App
-
hp_info

From the above sequence diagram, the following classes are used:
-
FacadeController
-
App
which I use to showing when the Distribution button is clicked.
Design Patterns Used
From my project, I have used the following design patterns:
- Facade Pattern
I have used the facade pattern to provide a simple interface to the complex subsystem of the Harry Potter data set. The facade pattern is used to hide the complexity of the system and provide a simple interface to the user.
Graph Algorithm Used
Determine who has the most enemies, who has the least enemies, and who is the friendliest with whom.
Algorithm:
- WhateverFirstSearch (BFS, DFS)
Other Information
Interesting in the project:
- matplotlib.backends.backend_tkagg
From this module, I have used the FigureCanvasTkAgg class to display the matplotlib figure in the tkinter window.

-
Description This program will show the graph of OHCL chart and it can compare with the other value to see the graph of these 10 best performing stock on 2021 By yahoo! Finance.
-
Data Sources The Dataset of this program is provided by yahoo! Finance API https://pypi.org/project/yfinance/ that contain record of each company stock value by date-time.
10 Company that I choose is came from this news https://finance.yahoo.com/news/top-10-best-performing-stocks-190949855.html

Footnote
GitHub link: https://github.com/D7NAMITE/Footnote
Overview
Footnote is the program that comapre the data from online book store(included Meb, Naiin and Ookbee) to provide the cheapest out of the selection.
Features
- Full-tkinter based GUI
- Search the book from three source
- Meb
- Naiin
- Ookbee
- Display the graphs (Ex: Histogram of Book Price, Scatterplot of the Book Price and Rating)
- Compare the book price

Description: The Application is for data visualization of top tracks on Spotify and how the elements of the song (i.e. danceability, genre, explicit, etc.) can affect the popularity score of each song (higher means more popular).
Users can choose parameters and graph types to visualize data and the application will show the graph on the screen.

Gekko Crypto Monitorring App. Description Gekko crypto monitorring app is a Python program that creates a simple GUI that allows the user to select a cryptocurrency and plot its historical price data in various graph types such as line plot, histogram, and box plot. The program uses the tkinter library for creating the GUI and the requests, seaborn, pandas, and matplotlib libraries for retrieving, cleaning, and plotting data.
The program retrieves a list of cryptocurrency names from the CoinGecko API and populates a list box in the GUI with these names. When the user selects a cryptocurrency and a graph type, the program retrieves the historical price data for the selected cryptocurrency using the CoinGecko API and plots the data in the selected graph type.
Data Sources coingecko api = 'https://api.coingecko.com/api/v3/coins/'
Running the Application You can install dependencies by following command.
pip install -r requirements.txt Design The Gekko app is for a cryptocurrency price graphing tool, built using the Python programming language and the tkinter, requests, seaborn, pandas, and matplotlib libraries. It is designed to allow users to select a cryptocurrency from a list of options and display its price chart using one of three different graph types: a histogram, a line plot, or a box plot.
Design Patterns Used The Gekko cryptocurrency monitoring application follows the Singleton design pattern, which is a type of creational design pattern that allows for the creation of a single instance of a class. This ensures that there is only one instance of the class throughout the lifetime of the application, and provides a way for other parts of the application to access this instance globally.
Graph Algorithm Used You have a portfolio of cryptocurrencies and you want to know the most efficient way to convert your holdings into a target cryptocurrency, taking into account the exchange rates between the cryptocurrencies. Given a starting cryptocurrency and a target cryptocurrency, find the shortest path between the two, such that the path consists of no more than three edges. Return the sequence of cryptocurrencies and exchange rates that you should use to convert your holdings into the target cryptocurrency, such that you minimize your trading fees.
Vertices: Cryptocurrencies supported by Coingecko API
Edges: The edges between the vertices represent the exchange rates between the cryptocurrencies.
Associated Values: The edge weights represent the exchange rates between the cryptocurrencies.
Problem: Find the shortest path between two cryptocurrencies, such that the path consists of no more than three edges (i.e., at most two intermediate cryptocurrencies between the two given cryptocurrencies).
Algorithm: We can use Dijkstra's algorithm to find the shortest path between two cryptocurrencies, given that we have a weighted graph of exchange rates between the cryptocurrencies. We can modify the algorithm to terminate early if the path length exceeds three edges, and return the shortest path found within the specified limit. To implement this, we can maintain a count of the number of edges traversed so far, and terminate the search if this count exceeds three. If we find a path with two intermediate cryptocurrencies that satisfies the constraints, we can return this path as the shortest path. If we don't find such a path within the specified limit, we can return a message indicating that no such path was found.
Running time: O(ElogV)

For this project, I will be using information from an application that provides graphs showing nutritional information such as calories, fiber, vitamins, and more. The application has a total of three parts, each of which allows you to choose which information to display. The first part displays a chart of selected fruits, the second part displays a chart of selected vegetables, and the third part displays a chart of selected fruits and vegetables. You can choose from different chart formats, such as histograms or pie charts, for all three options.
main.py: This file serves as the entry point for the application and runs the program.container.py: This file contains the Container() class, which is responsible for pulling in different widget creations for the app.widget.py: This file contains the Widget() class, which is used for creating widgets that can be added to the Container() class.-
process.py: This file contains the GraphProcessor() class, which is dedicated to graphing nutrient data based on user input. -
Scenario for create a homepage(first page).


This application is designed to recommend board games based on user preferences. It takes in a range of desired player count, age, and playtime, then recommends the top 10 games fitting those criteria. It can also provide the top 30 games based on average rating, irrespective of the user's preferences. And we have 4 types of graph to be display about boardgames.

Avoid Accident 101
Description
Last year in Thailand there were a lot of accidents that are dangerous for everyone. My project is to create an app to find the best way to travel in thailand. My feature is to find the shortest path by using the dijkstra algorithm and app will show graph visualization.
Program flow
user input start province and destination province. program will suggest shprtest path to destination and show stat in chart
Data Sources
thailand_province_relations.txtrelations data fromgithubprovince.jsonsample latitudes and longitudes fromGPTaccident2022(eng).csvaccident data fromdatagov
Running the Application
pip install -r requirements.txt
if can't install basemap go to app.py and uncomment line 4 and comment line 5
Design Patterns Used
Use facade pattern to make the code more readable and easy to use.
App class is a facade class that will call other class to do the work.
Graph Algorithm Used
Dijkstra algorithm is used to find the shortest path between two nodes from Province s to Province t.

My application is the application use for search the anime. User can view the anime information by search by the title or genre etc. User can also view some graph.

MoodyBlues
Description
The app allows users to explore the environment that affects mental health through a series of graphs that users can freely choose to look for relationships of interest.
youtube link : https://youtu.be/VI4aRX8oNI0
Data Sources
Columns: *Note that column names in the program may differ.
Choose your gender (str), Age (int), What is your course? (unique str), Your current year of Study (int), What is your CGPA? (str), Marital status (boolean), Do you have Depression? (boolean), Do you have Anxiety? (boolean), Do you have Panic attack? (boolean), Did you seek any specialist for a treatment? (boolean)
Running the Application
Requirement
-
Python>= 3.7 w/ Tk/Tcl installed -
Pillow>=9.5.0 -
matplotlib>=3.7.1 -
pandas>=2.0.1 -
seaborn>=0.12.2 -
networkx>=3.1 -
tk_html_widgets>=0.4.0 -
beautifulsoup4>=4.12.2
You can install dependencies by following command.
pip install -r requirements.txt
Make sure you have all the required software installed.
~/ > git clone https://github.com/SirisilpK/year-project-Nantawat6510545543.git
~/ > cd year-project-Nantawat6510545543
year-project-Nantawat6510545543/ > python main.py
Design
Class Describe
Representation Layer
Frame Parent class for creating widgets of classes in this layer.
HomePage Program homepage
MainMenuPage Responsible for switching pages between DetailPage and VisualizePage.
DetailPage Shows the basic information of the program.
VisualizePage Take the input from the user, send it to VisualizeFacade and get the graph back to show it to the user.
Domain Layer
VisualizeFacade Facade class for data flow control and graphing
GraphMaker Creating graphs
NetworkGraph Creating network graph
Infrastructure Layer
DataFrameModifier Reading and editing data from csv files.
HTMLReader Read HTML files

Sequence diagram

The sequence diagram shows the situation in which the user wants to view the default graph.
Design Patterns Used
The program uses the facade design pattern to control the graphing and manipulate the data from the CSV. It also uses the singleton design pattern, which ensures that only one instance of a facade class can be created.
Graph Algorithm Used
Our project is to create an app that helps users learn about attribute relationships in our data. The graph algorithm facilitates the representation of the relationship between attribute A with attribute B in common.
If the user wants to know the relationship between attribute Ai and Aj with attribute B sharing It is found that Ai and Aj may not have a direct relationship. We therefore need the shortest relationship through the nodes.
Algorithm:
- Breadth First Search

example network graph showing relationship between each course and overall mental health sharing.
Other Information
extra module in the project:
-
tk_html_widgets
-
beautifulsoup4
I use these modules to increase the interest of the program. Using tk_html_widgets to display HTML into the program window using beautifulsoup4 to read the file. In addition to the basic charts, users can also select other charts as needed. You can find more information in the details.html or in the application.

Description
This project will use data set of game that sale for each game what the platform of that game and which region that sale this game . User can choose to show between sales rate and what type of game that publish for each year.
data source
My database for this application from https://data.world/sumitrock/video-games-sales
Running the Application
Dependencies
Here's are the list of necessary dependencies that I used in the project.
-tkinter
-pandas
-mathplotlib
You can install these dependencies by this command.
pip install -r requirements.txt

CineCreed
Description
CineCreed is an application for movie enthusiasts who want to dig and explore deeper into the movie industry. Users can visualize IMDb's movie database and compare between their interested selected movies.
Project Video Link: https://youtu.be/6jWHzEX3lIc
Screenshot

Data Sources
IMDb Movie Dataset: All Movies by Genre from https://www.kaggle.com/datasets/rajugc/imdb-movies-dataset-based-on-genre will be used in this project. It includes movie metadata such as movie name, total run time, genre, rating, director, and gross in($) from the IMDb website. The movie metadata from the dataset will be used for data processing and visualization.

Countries in the world is the year project about the visualization of data processing.
The user can see the various visualizations with more than 200 countries in the world.
These are our features in the application.
- User can see the general information of each country.
- User can see all the countries in each continent.
- User can see the statistic of various attributes through the visualization including various types of graph.


Description
Bangkok-RealEstate is a program that allows users to estimate real estate prices in different districts in Bangkok and can also compare prices of 2 districts to help users choose the right real estate for themselves.
Main Menu

Estimate Menu

Compare Menu

Statistic Menu

Data Sources
200k+ homes for sale in Thailand dataset from https://www.kaggle.com/datasets/polartech/200k-homes-for-sale-in-thailand. This dataset includes a lof of real estate ( 220557 row ) and housing attributes ( 69 column ) such as price, property_type, city, state, latitude, longitude, etc. In this program, 78550 row is used because it uses processed data.
Design
UML class diagram

Sequence diagram

Design Patterns Used
This program use facade pattern design. App class is a class that combines functions from class Estimate and GraphPlot and interaction with user.

Scented Luxe is an online perfume shop that is simulated using a graphical user interface (GUI) application developed in Python with Tkinter. The application allows users to browse and purchase perfumes from a product list. The application utilizes datasets, such as perfumes.csv, sellers.csv, and transaction.csv, which contain information about products, sellers, and transactions, including order details and sales statistics. The application presents the data in the form of tables and graphs, providing a visual representation of the perfumes and their sales performance. Users can easily navigate through the GUI to explore and purchase perfumes from the available product list.
GitHub link(last updated):https://github.com/SirisilpK/year-project-geeegrace02.git

Pokémon Scuffed Buddy
Description
Pokémon Scuffed Buddy is a program that can help you can find a stat of each pokemon, visualize data up to gen 5, and comapre two pokemon main type attack effectiveness.
Data Sources
Pokemon.csv contains all stat of pokemons up to generation 5.
-
: ID for each pokemon
- Name: Name of each pokemon
- Type 1: Each pokemon has a type, this determines weakness/resistance to attacks
- Type 2: Some pokemon are dual type and have 2
- Total: sum of all stats that come after this, a general guide to how strong a pokemon is
- HP: hit points, or health, defines how much damage a pokemon can withstand before fainting
- Attack: the base modifier for normal attacks (eg. Scratch, Punch)
- Defense: the base damage resistance against normal attacks
- SP Atk: special attack, the base modifier for special attacks (e.g. fire blast, bubble beam)
- SP Def: the base damage resistance against special attacks
- Speed: determines which pokemon attacks first each round
chart.csv contains hit effectiveness against each type.
Sources * https://www.kaggle.com/datasets/abcsds/pokemon * pokemon.com * pokemondb * bulbapedia
Running the Application
Dependencies * tkinter * matplotlib * pandas * networkx * seaborn * matplotlib * numpy * PIL
Design
Describe the overall design, including a UML class diagram and a sequence diagram of a selected scenario.
Class Diagram

- PokemonDataRecoder is used for reading data.
- PokemonManageer is the main class for the domain layer. it's doing all the logic.
- PokemonFacadeController is used for the representation layer to call all fuction from domain layer.
- App is the main windows of the program it can switch to all three pages which are
- PokemonStatPage is used to view selected pokemon's stat.
- PokemonGraphPage is used to view data virtualization of the data.
- PokemonCaparePage is used to compare two pokemons' type using Dijkstra's algorithm.
The following sequence diagram is for when the user choose pokemon to view it's stat
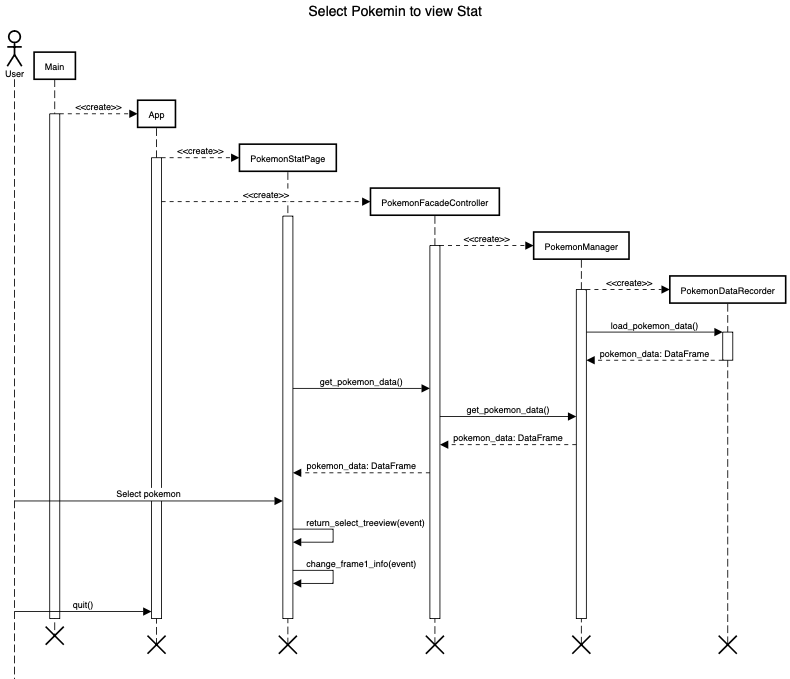
Design Patterns Used
The facade disign patterns is used for this program, so the representative layer doesn't have to mess with the domain, and infrastructure layer.
Graph Algorithm Used
User will select two pokemon, one pokemon is attacking, and the other defending. Every pokemon has an attack move with a different type, but in my program I assume that there are only the attack moves of the main type. Attack effectiveness can be normal, super very effective, super effective, and doesn’t affect. Up to the attacking and defending type. We assume effectiveness is a weight of the attack between two types. The user can select two pokemons and compare them, by the weight between two types.
- There is a vertex for each pokemon type. Assume there are n types.
-
There is a directed edge U -> V with weight that is up to effectiveness. For each type there is an edge to every other type.
- 0.5 for Super Effective
- 1 for Normal
- 2 for Not Very Effective
- 3 for Doesn’t Affect
-
Weight is the effectiveness between two types
- We need to find the shortest distance from vertex U to vertex V.
- We can solve this problem by using Dijkstra's Algorithm from vertex U to vertex V. and output dist[V].
- The algorithm runs in O(V+E) = O(n+(n-1)*n) = O(n^2)
- n type so three are n-1 edge for each type
Other Information
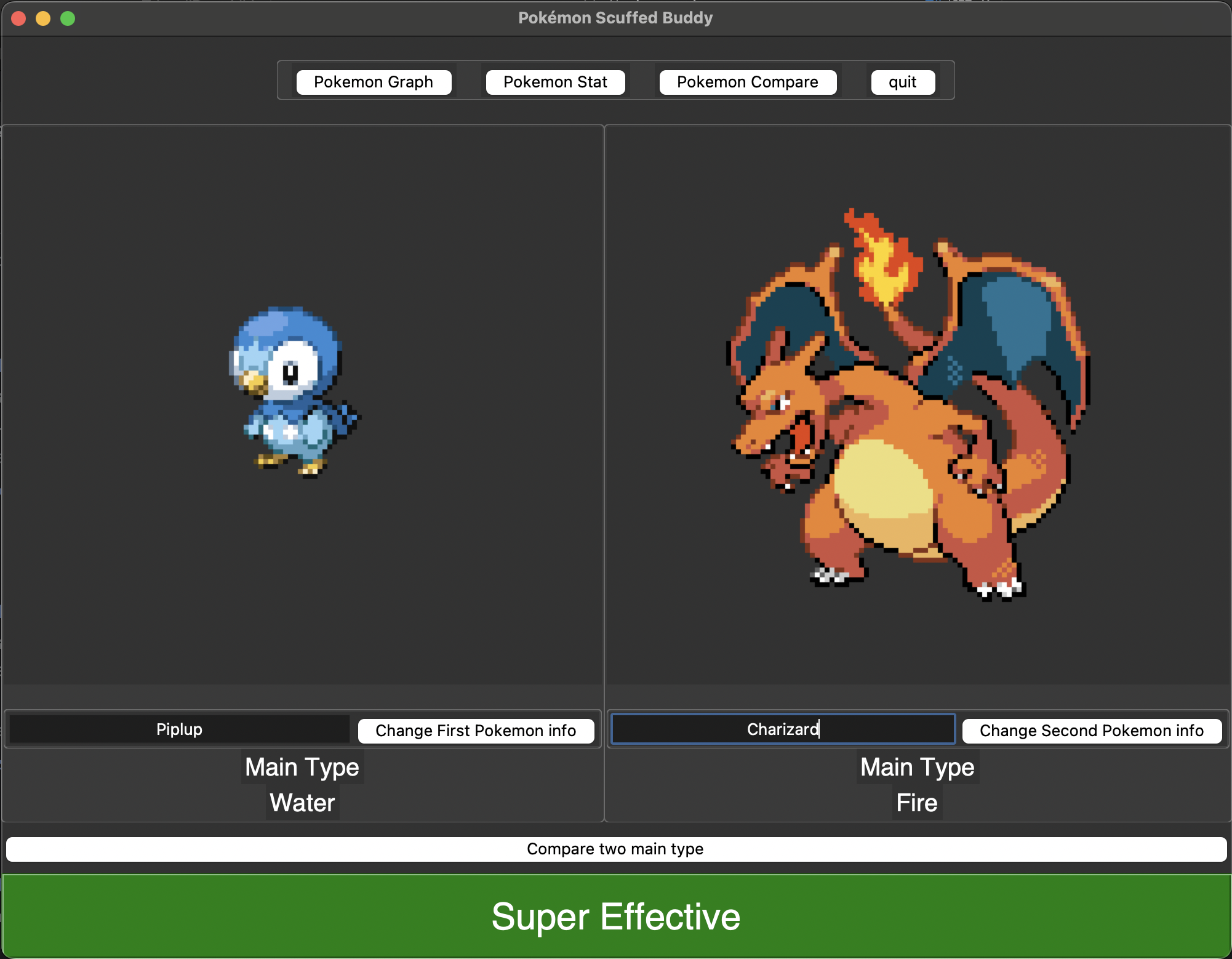
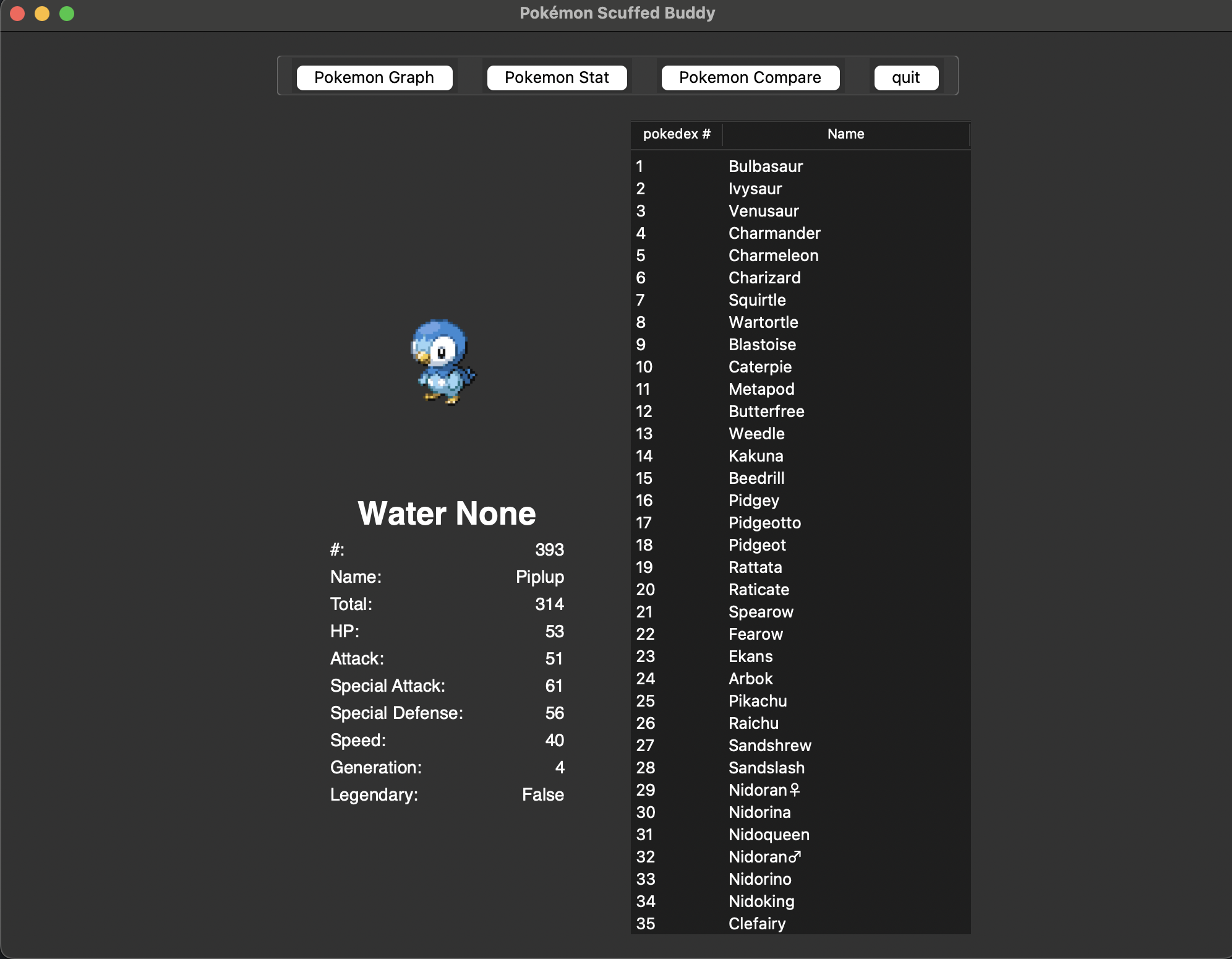
This is what the program look like when the user comnparing two pokemon types or checking pokemon's stat
The user can see pokemon's sprite that is selected

This application is about Online Banking that allow user to look at the transaction table and account table. Users can demonstrate transferring the money from one account to another account. Users also can see the graphs result from the transaction and account data.

Description
Sport Car Analysis is an application that shows different graphs, including everyday graphs (time series, part-to-whole), distribution graphs, and correlations.
Data Sources
Sport Car Analysis uses dataset from sport_car_data.csv and this source is from: https://www.kaggle.com/datasets/rkiattisak/sports-car-prices-dataset
Running the Application
Before running the application, users need to install the following packages:
pip install tkinter
pip install matplotlib
pip install pandas
After installing the packages, users can run the application by
running: main.py
Design
Here is my uml class diagram:
 Here is my sequence diagram:
Here is my sequence diagram:

In this application, we have 4 classes:
Appis a class that used to provides a user interface for users to view graphs.CarFacadeis a class that used to manage many methods, organize them, and export them to the GUI.GraphPlotteris a class that used to analysis data and create a graph.CarDatais a class that used to read data from a csv file and send it to other classes.
Design Patterns Used
In this application, I used the Facade design pattern that used to manage
many
methods, organize them, and export them to the GUI.
Graph Algorithm Used
In this project, we use graph algorithms to count car models from the relationships between different car models of the same make. We want to show the number of car models that have the same make by using the ComponentCount algorithm to find the number of connected components in an undirected graph.
Other Information
Through this project, I learned new things and got better at using Pandas, Tkinter, and Matplotlib.

Video Game Sales
Description
This application is an application represents publishers, genre, and sale of Video Games from each region.
Data Sources
vgsales.csv from kaggle. (https://www.kaggle.com/datasets/gregorut/videogamesales)
Running the Application
Install the dependencies using which are pandas, matplotlib, and tkinter. To run the application at main.py
Design
This program contains 3 classes, FacadeController, App,and VgSales.
Design Patterns Used
I used Facade pattern to provide a simple interface to the user.
Graph Algorithm Used
I really love games from a publisher(ex. Nintendo) but recently this publisher is publishing games really slowly and I can’t wait. so I found another publisher that creates interesting games, but I’m not sure that I will like the game from this publisher or not. Is it worth it to buy the game from this publisher?
• There is a vertex for each publisher. Assume that there are n publishers • There is an undirected edge U → V if there is a game that was the same genre from each publisher. • The edges have no weight. • We need to find the reachability from vertex U to vertex V. • We can solve this problem using WhateverFirstSearch from vertex U, and check whether V is marked. • The algorithm runs in O(V + E) = O(n + n^2) = O(n^2) time.

- my dataset is about Video game sale data (ex. Rank, Platform, Publisher, Genre).
- user can compare between Sales of 2 video game from each country and can see the detail of each game
- this feature visualized in term of line graph , bar chart , pie chart , network

Restaurants Near Me



Description
Restaurant Near Me project is the application which users can search restaurant by category of restaurant, distance from user's location, city of restaurant and rating of restaurant in the main page. After user select data in combobox, The application will show location of each restaurant in the map. Users can also select Data Analysis menu in the menu button then the application will show descriptive statistics, distribution graph, Correlation and Part-to-whole graph which are analysis by restaurant data in Thailand.
Data Sources
My database for the application is from Kaggle.com
https://www.kaggle.com/datasets/polartech/300000-restaurants-in-southeast-asia-thailand
Running the Application
tkintermapview, requests, tkinter, matplotlib.pyplot, matplotlib.figure, matplotlib.backends.backend_tkagg
Design
UML Class Diagram

Sequence Diagram
for search button

Design Patterns Used
Using Facade Design Pattern in UI class for using Data, Map class (logic layer).
Graph Algorithm Used
I have use shortest path to find the nearest restaurant from user's location by using minimum of distance from user's location then the user can see the restaurant that is nearest from user's location
Other Information
My interesting packages in my application are request and tkinter mapview. I use request for finding user's location the request command will response the user's ip address and user's location: latitude, longitude. I use the latitude and longitude to mark user's location and also compute the distance from user's location and restaurant location so the user can see restaurant near the user's location

PM2.5 Static analysis will correct data from local data.csv using the Tkinter library in Python. It will visualize the data and graph using various plot types such as histograms, everyday graphs, and network graphs

Netflix Data Analysis
Description
This application will allow users to plot graphs between TV shows and movies to see the relationship between them. represent as a bar graph, line graph, or scatter plot. to see the descriptive statistics of each distribution.
Data Sources
Running the Application
dependencies (packages) needed to run your program
pip install panda
pip install matplotlib
pip install numpy
pip install networkx
pip install seaborn
pip install scipy \n
Run the application using the following command:
python3 main.py
or
python main.py
Design
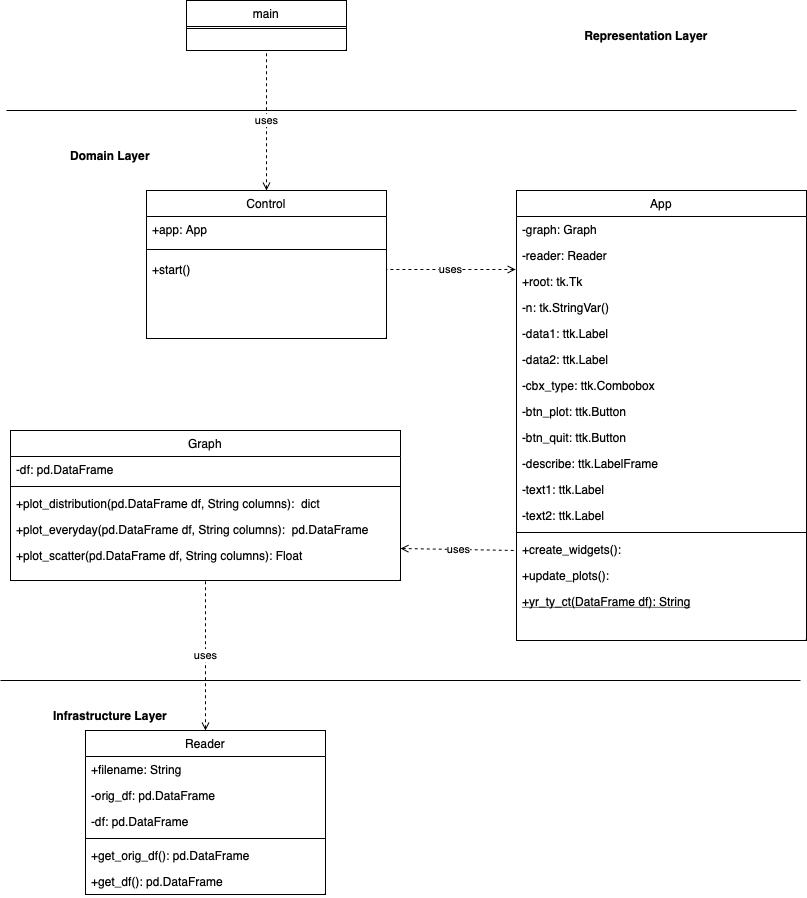
In the diagram, I have a main class that will run the application.
The main class will be called the Control class, which will be called the App class.
The app class will call the graph class and the reader class.
So Control classes act like facade patterns that organize the flow of the
program between user and application.
Design Patterns Used
Facade design pattern
Graph Algorithm Used
Our project is to build an application that analyzes data from the listings of
movies and TV shows on Netflix. If a user wants to watch a new movie but hasn't
picked one yet, our app can suggest new movies that have the same genres as the
ones they've watched before. We model the movie title as a graph problem as follows:
-
There is a vertex for each Movie title. Assume there are n movies
-
There is a directed edge p → q if movie have same genres assume as m related genres
-
The associate value will be how many genres didn’t match
(if all genres don’t match a single one, that node will not have edges) -
We need to find the shortest path from one movie title to all nodes (Movie title)
-
We can solve this problem by using BreadthFirstSearch from lasted movie title,
and output the distance array
The algorithm runs in O(V+E) = O(n+m) time
Other Information
interesting libraries used in your project
scipy.stats
is used to calculate the correlation coefficient between two variables.
matplotlib.backends.backend_tkagg
is used to display the graph in the GUI.

The EV ChargingStation Analysis App that provides visualizations and analysis of electric vehicle charging stations in the US. It allows users to explore data related to the charging stations, such as the distribution of stations across states and the growth of stations over time.

Users can choose what data they want to know such as infected people, Recovered people. I use the covid19-data set in Thailand form https://covid19.ddc.moph.go.th/
Description
Packaged Food Explorer is GUI application that explore and analyze packaged food dataset
Data Source
https://world.openfoodfacts.org/data
Quick start
1) Clone github repository
git clone https://github.com/Sosokker/Packaged-Food-Explorer
2) pip install
pip install -r requirements.txt
3) To start GUI window run app.py
NOTE
- Process data with file main.ipynb need .csv file from Data Source
- If error about "food_data.db" occur download food_data.db and put in folder data
Github

FOOTBALL11 SQUAD PICKUP
Decription
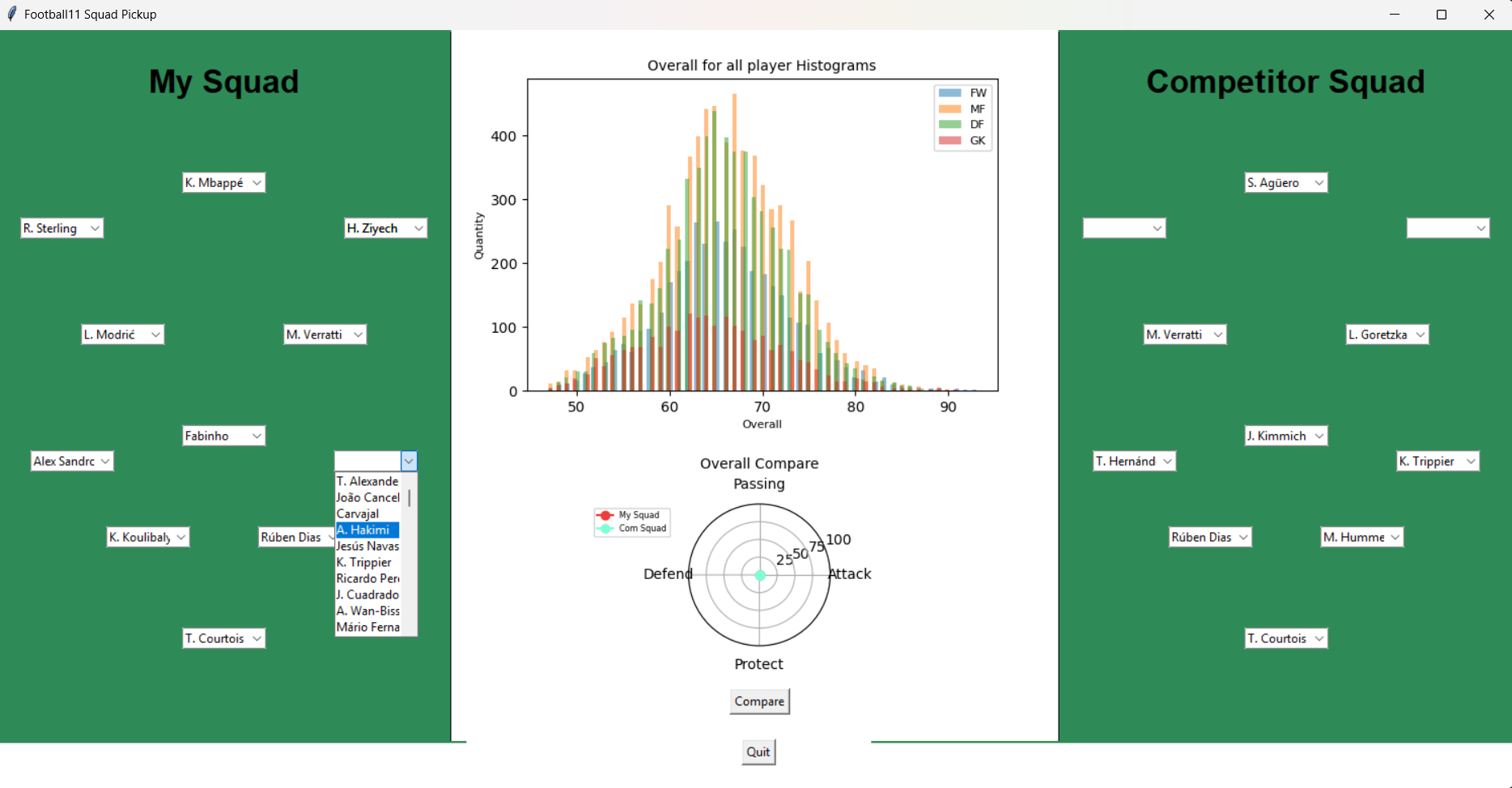
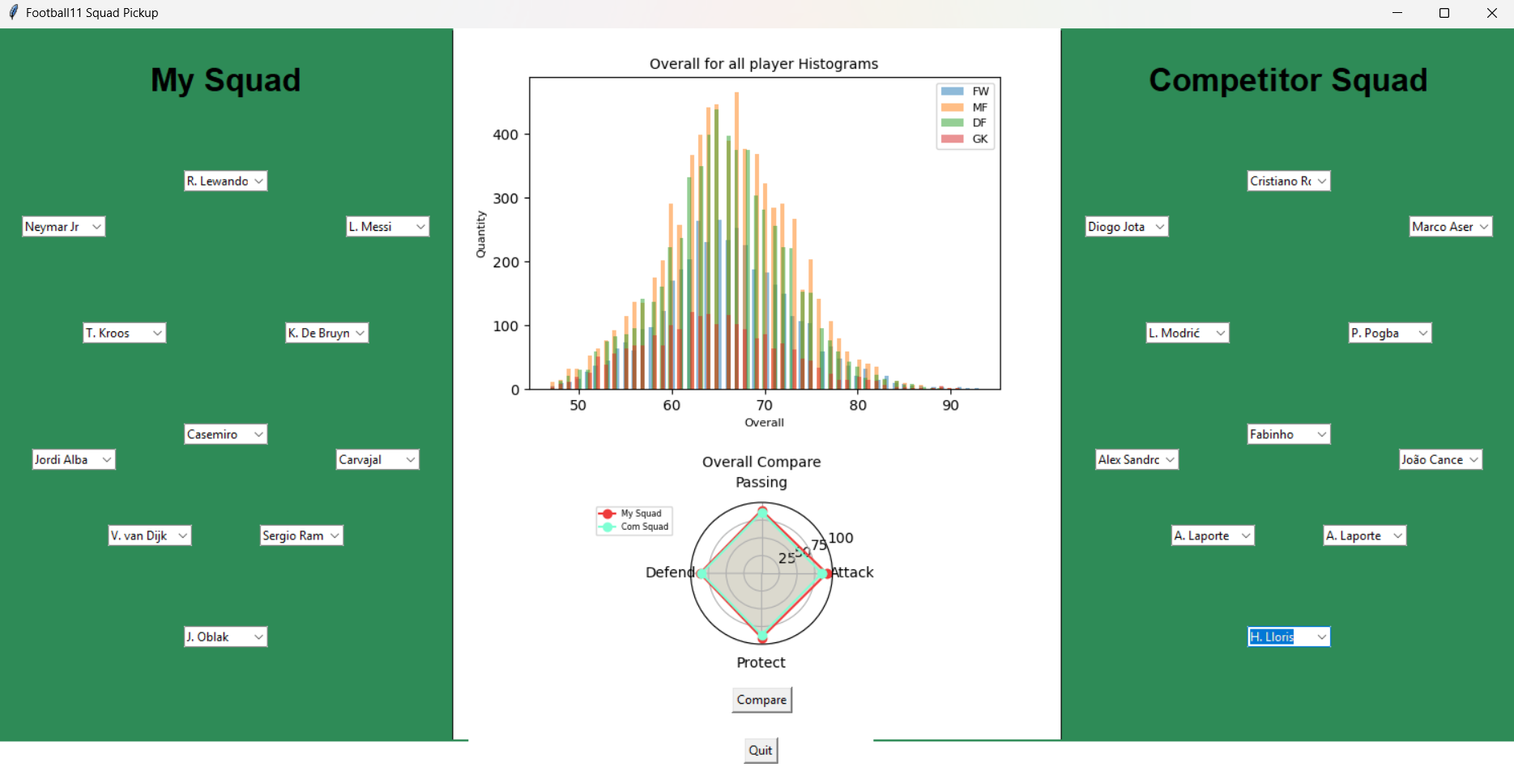
For this project, I make a football squad pickup program. In this program, you can select your own football player for each position in your squad and also can select the football player for the competitor squad. Each player, they have an overall stat. After you select your football player, you can click compare button that places in the middle of the screen then the program will calculate the overall for 4 topics namely Attack, Passing, Defend and Protect then it will show the compare result in the radar graph.
- Attack => ST, CF, RW, LW
- Passing => CM, CAM, CDM, LM, RM
- Defend => CB, RB, LB
- Protect => GK
In addition, in the middle top of UI, I represent the overall stat from the example group of football players in terms of a histogram graph.
Instrution
Step
- Click on each combo box to select your football player.
- Click on Compare button to compare the overall stat. The result will show in a radar graph.
- You can change football players as mush as you want. But every time that you change, you need to click on compare button to show the result.

- If you want to quit the program, click on the Quit button at the bottom of the program.
Code
main.py: In this file, I use to do mainloop and run program.MySquadManagement.py: In this file, I use to load the data fromplayer_22.csvfile. It return list of data.My_Squad.py: In this file, I use to separate the data from theMySquadManagementlist and return list of each data.Graphic: In this file, I use to make all GUI graphic and calculate the overall stat then create the graphplayer_22.csv: The data sort. link
Diagram
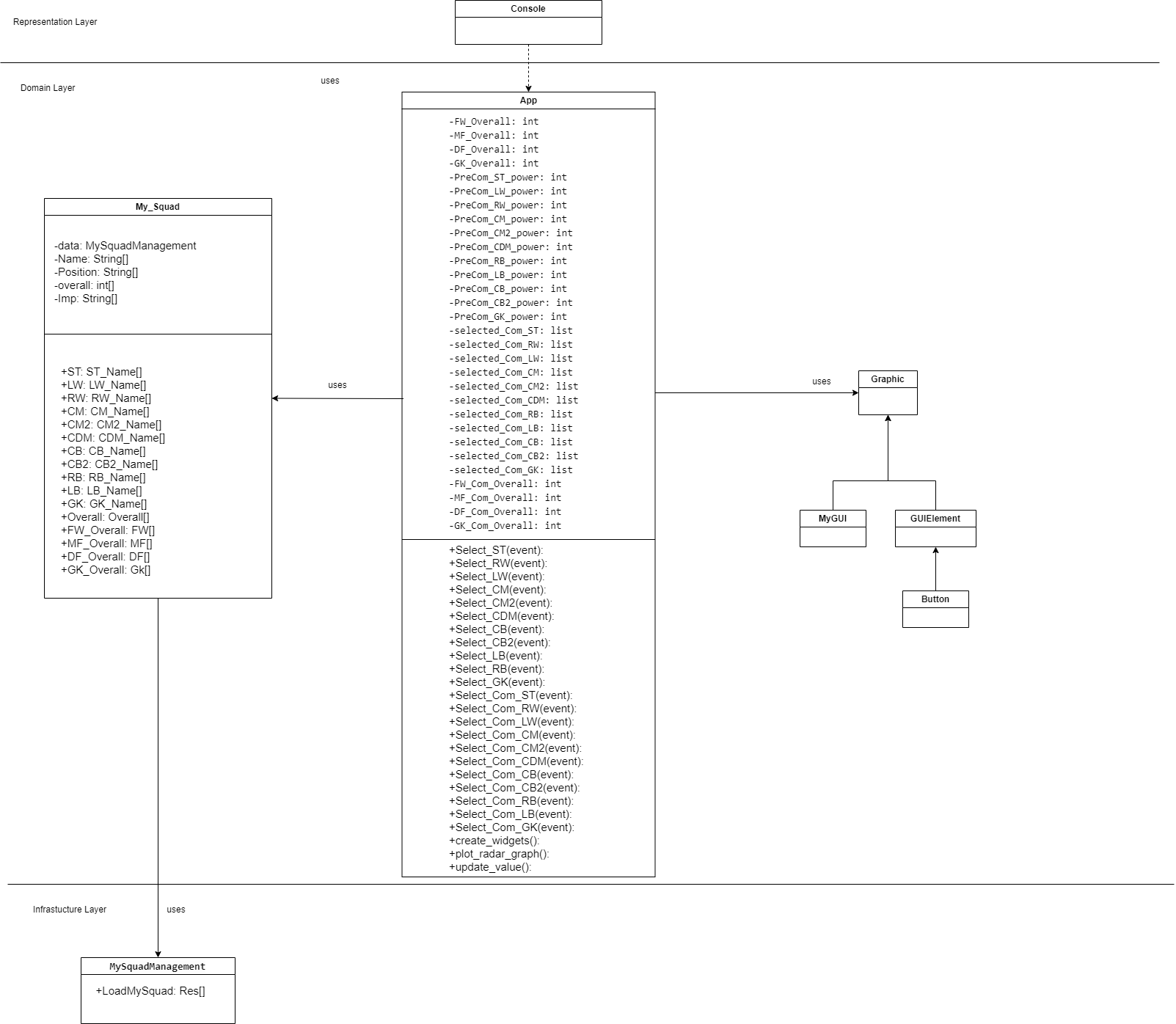
Github

The Spotify Country Analyzer is a graphical user interface (GUI) application that allows users to analyze and visualize Spotify data based on different countries. The application provides features such as filtering songs by country, displaying top ten songs, searching for specific songs, and plotting graphs to analyze the data. The GUI provides an interactive interface for users to explore and understand Spotify music trends across different countries.
you have to download the csv files by this link - https://www.kaggle.com/datasets/dhruvildave/spotify-charts

The spoticult application is Song data visualize app that can visualize attributes of the song that is selected by users and users can also add songs to the playlist that user can see the graph that provide average of attributes of songs in the playlist

This program is grade calculate and visualize statistic of exam score program. We can modify the graph freely It can do with any csv file that have the same formula (columns: ID,Name,subject1,subject2...). And can analyze what group of student should the selected student by use graph
Data Sources
Use exams.csv file from https://www.kaggle.com/datasets/adepvenugopal/exam-scores (edit data set to have form id name subject in column )
Running the Application
run program by mian.py using following libraries
-tkinter
-matplotlib
-networkx
-pandas
Design
main class : for running the entire program
App class : facade class that using all of class in program and create gui
Graph calss : for visualize all type of graph except network graphv
Grading class : calculate grade
statistic class : calculate statistic
Network class : perform network graph and contain graph algorithm
Student class : contain student data for use in network graph
CsvRead class : read csv by using pandas
Design Patterns Used
Using facade and layered architecture pattern by the facade class is App class which is use and initialize other objects include Grading ,Graph ,Network ,statistic and student class and all of these object using dataframe that read from CsvRead class
Graph Algorithm Used
Analyze student score to help user can decide what group of selected student should be in for do any group works. By visualize the network graph and solve graph problem to find similarity of each student. By Find list of students who have n(n is number of people in 1 group) first shortest path to selected student. Use dijkstra’s algorithm from selected vertex to all vertex.

Your Application Name
Youtube's Stats
Description
this project is about analyzing statistic of Youtube videos based on viewer in UnitedState with data from the USvideos.csv file that contains the information of Youtube video's view , video_title , channel_name ,date_publish and video's title this application will show user the information of videos view statistics , displayed in graphs according to user's selected topics ex. top most viewed video or channel with highest total views etc. by options as a button for each type of datas for user to choose



Data Sources
the csv file containing Trending YouTube Video Statistics https://www.kaggle.com/datasets/datasnaek/youtube-new
Running the Application
tkinter : use for making GUI and show graphs matplotlib : also use for plotting graphs seaborn : use for plotting line graph pandas : use for managing datas mainly from csv file
Design
There are three classes , Facade , Menu and Option
simply put Facade is the front door that uses Menu while 'Menu' contains
choices of options which operate according to each options in class 'Option'
ClassDiagram:

SequenceDiagram of showing channels view stats:

Design Patterns Used
facade design pattern by having facade uses the others classes
Graph Algorithm Used
Describe the part of your application that is modeled as a graph problem (reachability, shortest path, 2-coloring, etc.), and the algorithm used to solve it.
Other Information
github-link : https://github.com/SirisilpK/year-project-ChamarakGajaseni.git

Airport Rail Link 2565 Schedule Analysis and Visualization
Description
The application is a data exploration and visualization tool that allows users to interact with a dataset containing information about Airport Rail Link train schedules. The user can filter the dataset based on various criteria, such as the train station, day of the week, or date.
The processed data is then visualized using various charts and graphs, including bar charts, line charts, and scatter plots.
Demonstration Video
https://youtu.be/XURPse8nS7U
Start Up
Select Option
Select All Option
Data Sources
The dataset used in this project is a csv file from this website https://datagov.mot.go.th/dataset/drt2566_02
Running the Application
Python version 3.10 or higher
Required library to run:
- tkinter
- tkinter ttk
- numpy
- pandas
- abc (ABC, abstractclassmethod)
- matplotlib.pyplot
- matplotlib.figure
- matplotlib.backends.backend_tkagg
All of these expect numpy and pandas is pre-installed with Python. You should be able to import it directly.
For numpy, use -pip install numpy For pandas, use -pip install pandas
Then you should be able to import it now.
Design
-
This program is mostly composed of composition relationships, there are also inheritance relationships with DropdownMaker to each dropdown types.
-
This program tries to separate each class' responsibility, for example ARLManager only manages the dataframe and do not do anything else.
Class Diagram:
- ARLGUI class, this is main class
- GUIFacade class, this is the class for interacting with all the GUI
- ARLManager class, this class is for filtering and modifying dataframe into table and graph dataframe
- DropdownMaker class, this class is for making Dropdowns
- FilterOptionMaker class, this class is for making filter option dropdown
- FilterSuboptionMaker class, this class is for making filter sub-option dropdown
- IntervalOptionMaker class, this class is for making interval option dropdown
- IntervalSuboptionMaker class, this class is for making interval sub-option dropdown
- ARLVisualizer class, this class is for setting up the matplotlib graph components, such as figure, axis, canvas, etc.
- DistPlotter class, this class is for plotting distribution graphs
- EverydayPlotter class, this class is for plotting everyday graphs
Sequence Diagram:
Design Patterns Used
This program uses Facade design pattern to hide the complexity for the GUI
Graph Algorithm Used
I use the graph algorithm to determine the path with the lowest passengers from station A to station B. For example, if I want to go to station A4 from station A1, there are many ways I can go, but there will always be a path that has the least amount of passengers, which can use the shortest path algorithm to find as well.
- Vertices are represented by each train station, there are n stations
- Edges are represented by the path between each station, there are m paths. Edges are undirected.
- The edges have weights, which is associated by the average of the inbound and outbound passengers, which is non-negative.
- Given an undirected non-negative weight graph G and a vertex s in G,
- We need to find the shortest path from vertex A to vertex B.
- We can solve this problem by using NonNegativeDijkstra’s Algorithm from A to B, and output the path array
- This algorithm runs in O(ElogV) = O(mlogn) time.

- What dataset(s) will be used in the project. Ans I will use data base from https://dbkpop.com/db/k-pop-idols-from-japan/ and then convert to csv.
- How your application will interact with the user, e.g., what data processing parameters can be controlled by the user. Ans User can see the information which demonstrate by graph such as are the more male or female Japanese idols in K-POP industry. 3.How will the processed data be visualized (e.g., what will the charts or animation look like). Ans It will be pie chart or bar graph

Description
This project is an application that showcases popular movies from the IMDB database, allowing users to search and sort the data. You can also visit the IMDB website for more information about the film. And the data can be analyzed from graphs where users can select the type of graph and the data they want.
Data Sources
My database for using in this project from www.kaggle.com
Running the Application
go to main.py to run this application and You must be connected to the Internet while using this application.
Other Information
modules used in this project - tkinter - seaborn - matplotlib - PIL: use to open image - webview: use to display web content within a desktop application - matplotlib.backends.backend_tkagg: use to create Matplotlib figures and plots and display them within a Tkinter application, in Scatter graph part - matplotlib.backends._backend_tk: use to create toolbar in Scatter graph part

- dataset: receive input of daily money saving from user in 1 dataset will have (income, paid, total, saving, order)
- Receive input of daily saving and payment of user User can watch statistic of money saving and using in line graph and can watch percentage of payment in each order in daily compare to total payment in daily.

This application is for people who want to know the ranking of anime rank by rating and members. User can choose the genres of anime, rank by(rating and members) and sort by(descending and ascending) it will show the table of data of anime ex. anime name, episodes etc. that sort by filter that user choose. Final option is user can plot rank by values with barplot and boxplot to show averages of values with type of platform that display the anime.

ValoVajai is a user interface that displays data and graphs related to the professional Valorant teams and players in the VCT competition. It provides valuable insights into team and player performance, match schedules and results, and key metrics to help users better understand the VCT tournament. The data is sourced from the official VCT website at VCT
The data was obtained from the following Kaggle dataset: Kaggle
-
ValoVajai uses the Model-View-Controller (MVC) pattern to separate the data and business logic from the user interface. The Observer pattern is used to update the view when there are changes to the data. These patterns make the code more organized, maintainable, and scalable.
-
This program has a visual interface that users can interact with to view information about the game Valorant and create graphs. It uses a library called tkinter for the visual elements and libraries called matplotlib and networkx to create the graphs.
 - This is the login page where the user needs to enter their username and password to log in. If the user has not registered yet, the Register button will not be
- This is the login page where the user needs to enter their username and password to log in. If the user has not registered yet, the Register button will not be clickable.
https://github.com/dzptahh/ValoVajai/blob/master/login2.png - If the user tries to register with incomplete information, an error message will appear saying "Registration failed. Please enter all information" to prompt the user to enter all required information.

Equalize

Description
Equalize is a regression and analysis program, Its main function is to visually represent processed data using different types of graphs. Additionally, it can also utilize basic machine-learning techniques to make predictions based on the data.
The program's detail is in README.md
Data Sources
The Gender Inequality Index (GII)
This project will use example student GPA dataset(current format of choice is csv). The application will ask which student user want to look into and visualized the data into simple graph, which will make it easier to read. It will also show distribution of the student GPA compare to overall student in the dataset.