รายการโครงงาน
01204162 Applied AI for Engineering
ภาคปลาย ปีการศึกษา 2567 หมู่ 1
ที่มา
นิสิตสนใจในงานด้าน image processing เพื่อพยายามไปประยุกต์กับงานวิศวกรรมสิ่งแวดล้อม โดยเริ่มต้นจากการสร้าง ML สำหรับการตรวจสอบพื้นของสถานที่ต่างๆว่ามีกองขยะ อยู่บนพื้นหรือไม่ ซึ่งนิสิตจะนำหลักการจาก project นี่ไปประยุกต์ ในการสร้าง ML ในการประยุกต์ในด้านที่สนใจ
วิธีการ
preprocessing
นิสิตได้นำ data set จาก kaggle มาใช้เป็น data set หลักเนื่องจากการทำ MLต้องใช้ข้อมูลมากพอสมควร โดยนิสิตจะทำ data augmentation โดยการนำรูปไปปรับโดยที่สึของภาพและหมุนรูป และนำสิ่งที่ปรับเพิ่มเข้าไปใน array ของ data แล้วนำรูปไป rescale ให้ขนาด 224*224 pixel แล้วนำ data ไป normalize โดยการนำไปหาร 255
build model
โดยนิสิตจะใช้โมเดล convolutional neuron network และ ปรับค่า Optimizer โดยเลือกมาเพียง 2 รูปแบบโดย มี ADAM , RMSprop แล้วทดลองนำโมเดลมา classification ในงานจริงๆแล้วลองสรุปผล
แหล่งข้อมูล

แรงบันดาลใจ
Material informatic นับว่าเป็นศาสตร์ใหม่ในวงการวัสดุที่กำลังเริ่มเติบโต และด้วยปัจจุบันที่การเข้าถึงข้อมูลทางด้านวัสดุที่มีข้อมูลจำนวนมากขึ้น จึงนับว่าเป็นวัตถุดิบที่ดีในการนำมาใช้เป็นข้อมูลเพื่อป้อนแก่ Machine Learning ให้กระบวนการในการค้นหา คัดเลือก และออกแบบวัสดุเป็นในแนวทางที่มีประสิทธิภาพมากขึ้น ทั้งการลดการสูญเสียของวัสดุที่ใช้ในการสังเคราะห์หากวัสดุที่ตั้งเป้าไว้ไม่ตรงกับเป้าหมาย และสามารถลดเวลาในการทำนายด้วยวิธีการ simulation แบบดั้งเดิมที่ต้องกินเวลาและใช้ศาสตร์ความรู้เข้าร่วมด้วย
แหล่งข้อมูล
ฐานข้อมูล: The Materials Project
รายละเอียด: ดึงชุดข้อมูลด้วย API จากนั้นทำการปรับข้อมูลที่มีการบันทึกแบบข้อความให้เป็นตัวเลข เนื่องจากจะทำการทำนายด้วยการ regression
วิธีการ/เทคนิคที่จะนำมาแก้ไข
รายละเอียด: ให้โมเดลหาความสัมพันธ์ของแต่ละฟีเจอร์ และการปรับตัวโมเดล ค่า Hyper parameter เพื่อหา combination ที่เหมาะสมที่สุดสำหรับวัสดุกลุ่ม Pyrosilicate/disilicate
รายงานผล
รายละเอียด: รายงานผลการเปรียบเทียบความสามารถในการทำนายของแต่ละโมเดลและ hyper parameter ที่เลือก
ดาวน์โหลดไฟล์โครงงาน
เนื่องจากไฟล์งานมีขนาดใหญ่เกินไป (116 MB) ขออนุญาตอัพโหลดผ่าน google drive แทนครับ Download ที่นี่

ใช้ข้อมูล datasets ของโรคที่เกิดในองุ่นจาก kaggle โดยตรวจจับภาพของใบองุ่นว่าตรงกับโรคชนิดไหน เพื่อใช้ในการควบคุมคุณภาพของต้นองุ่นก่อนการเก็บเกี่ยวผลผลิต ซึ่งส่งผลต่ออุตสาหกรรมองุ่น ทั้งการผลิตและคุณภาพขององุ่นที่ใช้ในการทำไวน์ น้ำองุ่น และการบริโภคสด เพื่อความปลอดภัยในการบริโภค

ที่มา
เวลาลูกค้าฝากเงินไว้กับธนาคาร เงินก้อนนี้ไม่ได้ถูกปล่อยทิ้งไว้เฉยๆ แต่ธนาคารนำไปลงทุนต่อ เช่น ปล่อยกู้ ดอกเบี้ยสินเชื่อ ลงทุนในพันธบัตร หรือธุรกิจอื่นๆ เพื่อสร้างรายได้ ถ้าลูกค้าอยู่กับธนาคารนาน เงินฝากของลูกค้าก็กลายจะเป็นแหล่งทุนระยะยาวที่ช่วยให้ธนาคารมีสภาพคล่อง และทำกำไรได้อย่างต่อเนื่อง เเต่หากลูกค้าถอนเงินออกจากบัญชี หรือปิดบัญชีไป ธนาคารจะเสียแหล่งเงินทุน เเละยังต้องเสียต้นทุนเพิ่มขึ้นในการหาลูกค้ารายใหม่หรือดึงดูดเงินฝากจากแหล่งอื่นซึ่งมักมีต้นทุนสูงกว่า ดังนั้น การทำ Bank Customer Churn Prediction จึงสามารถที่จะใช้ทำนายได้ว่าลูกค้าคนไหนมีแนวโน้มที่จะเลิกใช้บริการ ซึ่งก็สามารถเป็นการรักษาลูกค้าไว้ได้ก่อน โดยอาจจะมีวิธีการต่าง ๆ เช่น การเสนออัตราดอกเบี้ยที่จูงใจ, การให้บริการที่ตรงใจและสะดวกขึ้น, การมอบสิทธิพิเศษ หรือโปรโมชั่นเฉพาะกลุ่มได้ เป็นต้น
เเหล่งข้อมูล
Dataset ได้นำเอาชุดข้อมูลมาจาก Kaggle ซึ่งเป็นข้อมูลของธนาคาร ABC (Arab Banking Corporation) มาศึกษา (https://www.kaggle.com/datasets/gauravtopre/bank-customer-churn-dataset)
วิธีการ
ใช้ Machine learning โดยมีวิธีการ คือ มีการเตรียมข้อมูล (Preprocessing), ใช้ Logistic Regression Model, มี Polynomial Feature, มี SMOTE, มีการ Prediction, มีการวัดประสิทธิภาพจากตัววัด 3 ตัว คือ Confusion Matrix, ROC curve เเละ Weight F1 score

ที่มาและปัญหา
เนื่องจากทุกวันนี้โรงงานอุตสาหกรรมการผลิตมากมายในประเทศไทย การที่มีเครื่องจักรเข้ามาช่วยในการผลิตสามารถลดจำนวนคนงาน และเพิ่มจำนวนการผลิตได้มากในเวลาที่จำกัด แต่ถึงอย่างไรนั้นเครื่องจักรไม่สามารถที่จะสามารถรับรู้ความผิดพลาดในรูปแบบภาพ vision ได้ จึงได้มีแนวคิดริเริ่มเกี่ยวกับการทำโปรเจคเกี่ยวกับ การตรวจสอบความผิดปกติของการใส่ฝา บนสายพานลำเลียงในโรงงานอุตสาหกรรม เนื่องจากเป็นสิ่งที่อยู่ใกล้ตัวในชีวิตประจำวัน และเป็นการนำองค์ความรู้ 2 อย่างเข้าด้วยกันของทางวิศวกรรมเครื่องกล และวิศวกรรมคอมพิวเตอร์ ถึงแม้ว่าทุกวันนี้จะมีกล้องสำเร็จรูปตรวจสอบฝาขายแล้วก็ตาม แต่ย่อมมีราคาที่สูง การที่เราเข้าไปศึกษาเรียนรู้เกี่ยวกับ AI vision นั้น สามารถที่จะนำไปประยุกต์ได้อีกมากมาย
วิธีการ
ใช้ roboflow สำหรับการเตรียมข้อมูล dataset เพิ่มจำนวนโดยการเพิ่ม augmentation เช่น flip rotation และอื่นๆ กำหนดขอบเขต label ของภาพเพื่อกำหนด class ของวัตถุ ประกอบไปด้วย sealed cap คือ ฝาขวดน้ำที่ปิดได้อย่างสนิท loose cap คือ ฝาขวดน้ำที่ปิดไม่สนิท และ missing cap คือ ไม่มีฝาอยู่เลยบนขวดน้ำ หลังจากเตรียม dataset จะใช้ yolov8 ซึ่งเป็นอัลกอริธึมสำหรับ Object Detection ที่สามารถตรวจจับวัตถุหลายประเภทในภาพเดียวกันได้อย่างรวดเร็วและมีประสิทธิภาพสูงเป็นการ train ML เพื่อนำโมเดลที่ได้มาใช้งานภายหลัง
แหล่งข้อมูล
เป็นภาพถ่ายจากโทรศัพท์มือถือที่ถ่ายด้วยตัวเอง class ละประมาณ 600 รูปภาพ ประกอบไปด้วย sealed cap loose cap และ missing และทำเป็นการเพิ่ม augmentation ใน roboflow เป็นคลาสละประมาณ 6000 ภาพ รวมประมาณ 18000 รูปภาพหรืออาจมากกว่านั่น เพื่อเพิ่มประสิทธิการทำงานของโมเดล ข้อมูล dataset อยู่ใน link นี้ครับ https://drive.google.com/drive/folders/1gyEEwrE9md2-QBwElxWsZ34e4Z6QoILw?usp=sharing

ที่มา
การพัฒนาโปรแกรมพยากรณ์กำลังคอนกรีตมาจากความต้องการในการควบคุมคุณภาพของคอนกรีตในงานก่อสร้าง ซึ่งกำลังคอนกรีตเป็นปัจจัยสำคัญที่ส่งผลต่อความแข็งแรงและความทนทานของโครงสร้างคอนกรีตต่างๆ เช่น อาคาร, สะพาน, และสิ่งปลูกสร้างอื่นๆ การพยากรณ์กำลังคอนกรีตที่มีความแม่นยำจึงสามารถช่วยในการควบคุมคุณภาพของคอนกรีตและลดข้อผิดพลาดในกระบวนการผลิต และยังช่วยการประหยัดเวลาและต้นทุนเพราะการทดสอบกำลังคอนกรีตในห้องปฏิบัติการอาจใช้เวลาและค่าใช้จ่ายสูง
แหล่งข้อมูล
ดาวน์โหลดจาก UCI Machine Learning Repository https://archive.ics.uci.edu/ml/datasets/concrete+compressive+strength
วิธีการ/เทคนิค
วิเคราะห์ข้อมูลแบบ EDA - Exploratory Data Analysis Machine Learning Models : ใช้ทั้ง Linear Regression และ Random Forest Prediction: พยากรณ์กำลังของคอนกรีต
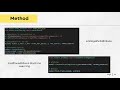
ที่มา เวลาเราทำการก็สร้างตึก อาคาร ขนาดใหญ่เราต้องสั่งวัสดุในปริมาณมากแล้วต้องมีการแบ่งสั่งเป็นเฟสๆ แล้วการสั่งแต่ละทีต่อให้ได้สัญญาในการสั่งซื้อในปริมาณมากทำให้ถูกกว่าซื้อในจำนวนน้อย โดยเฉพาะ วัสดุประเภทเหล็กที่มีการขึ้นลงค่อนข้างสูง ทำให้ เราเห็นว่าถ้าเรารู้ราคาคร่าวๆหรือแนวโน้ม เราสามารสตัดสินใจปริมาณในการสั่งซื้อได้ในแต่ละครั้งเพื่อควบคุมต้นทุนด้านวัสดุให้อยู่ในงบหรือต่ำกว่างบได้
แหล่งที่มา http://www.indexpr.moc.go.th/PRICE_PRESENT/SelectCsi_month_REGION.asp?region=0 เป็นราคาย้อนหลังของเหล็กเส้น https://www.bangchak.co.th/th/oilprice/historical?year=2020 ราคาน้ำมันย้อนหลัง https://wise.com/th/currency-converter/usd-to-thb-rate/history/31-03-2020 อัตราแปลกเปลี่ยนย้อนหลัง
วิธีการ/เทคนิค
Data Preprocessing: ทำความสะอาดข้อมูลและเลือก Feature ที่สำคัญ
Machine Learning Models: ใช้ทั้ง Linear Regression และ Random Forest
Model Evaluation: ใช้ Mean Squared Error (MSE) เพื่อวัดประสิทธิภาพโมเดล
Prediction: ทำนายราคาสำหรับข้อมูลใหม่

ที่มาของปัญหาและแรงบันดาลใจ : การชำรุดของอุปกรณ์ส่งผลให้เกิดการหยุดทำงาน ประสิทธิภาพการผลิตลดลง และค่าใช้จ่ายเพิ่มขึ้น จึงจัดทำ Machine Learning เพื่อทำนายและหลีกเลี่ยงการชำรุดของอุปกรณ์ด้วยการใช้เทคนิคต่างๆ
แหล่งข้อมูล/วิธีการรวบรวมข้อมูล : https://www.kaggle.com/competitions/playground-series-s3e17/discussion/416974 ข้อมูลมาจากการเก็บข้อมูลที่เกี่ยวข้องกับการใช้งานของอุปกรณ์ เช่น อุณหภูมิ การทำงาน การบำรุงรักษา ข้อมูลต้องมีคุณภาพสูงและสามารถเข้าถึงได้ง่าย เพื่อให้สามารถทำนายได้อย่างแม่นยำ
วิธีการ/เทคนิคที่ใช้ในการแก้ไขปัญหา : ใช้การวิเคราะห์เชิงพยากรณ์และการตรวจจับความผิดปกติของอุปกรณ์ด้วย Machine Learning, การตรวจจับความผิดปกติ (Anomaly Detection) วิเคราะห์รูปแบบการทำงานของอุปกรณ์เพื่อระบุพฤติกรรมที่ผิดปกติ ซึ่งอาจเป็นสัญญาณเตือนถึงความเสี่ยงในการชำรุด, การพยากรณ์ด้วยชุดข้อมูลเวลา (Time-Series Forecasting) ใช้ข้อมูลย้อนหลังเกี่ยวกับการทำงานของอุปกรณ์ เพื่อทำนายแนวโน้มของการเสื่อมสภาพและกำหนดเวลาที่เหมาะสมสำหรับการบำรุงรักษา, การพยากรณ์สุขภาพและการจัดการอายุการใช้งานของอุปกรณ์ (Prognostics and Health Management - PHM) ประเมินสภาพการทำงานของอุปกรณ์ในปัจจุบัน และคาดการณ์อายุการใช้งานที่เหลือ (Remaining Useful Life - RUL) เพื่อช่วยให้สามารถวางแผนการบำรุงรักษาเพื่อป้องกันได้อย่างแม่นยำ

เริ่มจากการใช้ model Predict Outcome ว่าเป็นเบาหวานหรือไม่จาก dataset จาก Kaggle มีการทํา EDA จัดการข้อมูลเพื่อเพิ่ม accuracy เมื่อเทียบกับการไม่ทํา EDA

ที่มา: เนื่องจากโรคอัลไซเมอร์เป็นภาวะสมองเสื่อมที่พบได้บ่อยในผู้สูงอายุ และมีแนวโน้มเพิ่มขึ้นอย่างต่อเนื่อง ทำให้เราต้องการที่จะทำนายการเกิดโรคด้วยปัจจัยหลายๆ ด้านเพื่อเฝ้าระวัง ป้องกัน และรักษา ผู้ป่วยได้อย่างทันท่วงที
วิธีแก้ไข: เลือกโมเดลทาง Machine Learning เพื่อใช้ในการคาดเดาการเป็นโรคอัลไซเมอร์ของประชากรจากปัจจัยด้านสุขภาพ ปัจจัยด้านประชากร และวิถีชีวิต
แหล่งข้อมูล: https://www.kaggle.com/datasets/rabieelkharoua/alzheimers-disease-dataset

ในปัจจุบัน สภาพภูมิอากาศที่เปลี่ยนแปลงตลอดเวลาและความแปรปรวนของสภาพอากาศส่งผลกระทบโดยตรงต่อสิ่งปลูกสร้างและโครงสร้างพื้นฐาน ไม่ว่าจะเป็นอาคารที่ก่อสร้างเสร็จแล้ว หรือโครงการที่กำลังจะเกิดขึ้น การเข้าใจปัจจัยทางสิ่งแวดล้อมที่มีผลต่ออายุการใช้งานของวัสดุก่อสร้างจึงเป็นสิ่งสำคัญ
เพื่อตอบโจทย์ความท้าทายนี้ เราได้นำเทคโนโลยีปัญญาประดิษฐ์ (AI) มาช่วยวิเคราะห์และทำนายอายุการใช้งานของวัสดุ เพื่อนำไปใช้ในการวางแผนการบำรุงรักษาให้มีประสิทธิภาพสูงสุด ตลอดจนช่วยประเมินสภาพแวดล้อมที่เหมาะสมสำหรับการก่อสร้าง และคาดการณ์ความทนทานของโครงสร้างที่ใช้งานมาเป็นเวลานาน การผสานเทคโนโลยีเข้ากับวิศวกรรมเช่นนี้ จะช่วยเพิ่มความปลอดภัย ลดต้นทุนการซ่อมแซม และยกระดับคุณภาพงานก่อสร้างให้เหมาะสมกับสภาพแวดล้อมที่เปลี่ยนแปลงอยู่เสมอ

เป็นการคาดการณ์ผลที่ได้จากการลงทุนต่อวันของแต่ละร้านกาแฟ โดยการใช้โมเดลแบบ regression

ที่มาของปัญหา/แรงบันดาลใจ
การพิมพ์ 3 มิติ (Additive Manufacturing) เป็นเทคโนโลยีที่ใช้กระบวนการสร้างชิ้นงานทีละชั้นจากวัสดุที่หลอมเหลวหรือพิมพ์ตามแบบที่กำหนด โดยสามารถสร้างรูปทรงที่ซับซ้อนได้โดยไม่ต้องใช้แม่พิมพ์ ทำให้การผลิตชิ้นงานที่มีความซับซ้อนสูงและปรับแต่งได้ตามความต้องการเป็นไปได้อย่างมีประสิทธิภาพสูง โดยเทคโนโลยีนี้มีบทบาทสำคัญในหลายอุตสาหกรรม เช่น อุตสาหกรรมเครื่องกล, ยานยนต์, การแพทย์, และอากาศยาน.
การพิมพ์ 3 มิติในปัจจุบันได้เข้าสู่กระบวนการของ Industry 4.0 ซึ่งเป็นยุคที่เทคโนโลยีล้ำสมัย เช่น Deep Learning, Artificial Intelligence (AI), Big Data, และ Computer Vision ถูกนำมาประยุกต์ใช้ในกระบวนการผลิตเพื่อเพิ่มประสิทธิภาพและความแม่นยำในการตรวจสอบข้อบกพร่องของชิ้นงาน. การใช้เทคโนโลยีเหล่านี้ทำให้สามารถตรวจจับข้อบกพร่องในการพิมพ์ 3 มิติได้อย่างอัตโนมัติและลดข้อผิดพลาดในการผลิต การพิมพ์ 3 มิติถือเป็นส่วนสำคัญของการพัฒนาใน New S-Curve ของประเทศไทย ซึ่งเป็นกลุ่มอุตสาหกรรมที่เน้นการพัฒนาเทคโนโลยีใหม่และนวัตกรรมที่มีศักยภาพสูง โดยการนำเทคโนโลยีนี้ไปใช้ในการพัฒนาอุตสาหกรรมที่มีมูลค่าสูงและสามารถแข่งขันในระดับสากลได้. การพัฒนาอุตสาหกรรมที่ยั่งยืน
การใช้ การพิมพ์ 3 มิติ ในการผลิตชิ้นส่วนในหลายอุตสาหกรรมยังสามารถช่วยส่งเสริมการบรรลุเป้าหมาย การพัฒนาอย่างยั่งยืน (SDGs) ขององค์การสหประชาชาติ โดยเฉพาะในด้านต่างๆ เช่น
- Goal 9: Industry, Innovation, and Infrastructure ซึ่งเน้นการพัฒนาอุตสาหกรรมและนวัตกรรมที่มีความยั่งยืน
- Goal 12: Responsible Consumption and Production ซึ่งเกี่ยวข้องกับการลดการใช้ทรัพยากรและการผลิตที่ไม่จำเป็น
- Goal 13: Climate Action ที่มุ่งลดผลกระทบจากการผลิตต่อสิ่งแวดล้อม
- Goal 8: Decent Work and Economic Growth ที่เน้นการเติบโตทางเศรษฐกิจที่มีคุณภาพและการสร้างงานที่มีความยั่งยืน
การใช้ Deep Learning และ Computer Vision ในการตรวจจับข้อบกพร่องในกระบวนการพิมพ์ 3 มิติช่วยเพิ่มความแม่นยำในการผลิต ลดการใช้ทรัพยากร และป้องกันการเกิดข้อผิดพลาดจากกระบวนการผลิต ซึ่งสอดคล้องกับเป้าหมายการพัฒนาอุตสาหกรรมที่ยั่งยืนและการใช้เทคโนโลยีที่มีประสิทธิภาพ.
แหล่งข้อมูลหรือวิธีการรวบรวมข้อมูล
ฐานข้อมูล : 3D printing process dataset
รายละเอียดข้อมูล ชุดข้อมูลนี้ประกอบด้วย 455 รูปภาพ ที่ถูกจัดหมวดหมู่เป็น 5 ประเภท ได้แก่ Normal, Bolhas, Overextrusion, Overextrusion10, และ Overextrusion40 ซึ่งแสดงถึงข้อบกพร่องที่เกิดขึ้นในกระบวนการพิมพ์ 3 มิติ (Extrusion Process) ตั้งแต่ช่วงเริ่มต้นจนถึงการประกอบชิ้นงานสำเร็จ
รูปภาพในชุดข้อมูลนี้เหมาะสำหรับการใช้ใน Computer Vision เพื่อฝึกฝนระบบตรวจจับข้อบกพร่อง โดยสามารถจำแนกข้อบกพร่องประเภทต่างๆ เช่น ฟองอากาศและการป้อนวัสดุเกินขนาด. ชุดข้อมูลนี้สามารถใช้ในการพัฒนา Machine Learning หรือ Deep Learning สำหรับตรวจจับข้อบกพร่องในกระบวนการผลิตได้อย่างมีประสิทธิภาพ.
วิธีการ/เทคนิคที่จะนำมาเเก้ไข
เทคนิคหลักคือ Supervised Learning และ CNNs สำหรับการจำแนกภาพ
-PyTorch (torch, torch.nn, torch.optim): ใช้สำหรับสร้างและฝึกโมเดลการเรียนรู้เชิงลึก Deep learning
-Convolutional Neural Networks (CNNs) (models จาก torchvision): ใช้สำหรับการจำแนกภาพ
-Data Processing (DataLoader, random_split, datasets): สำหรับโหลดและจัดการข้อมูล
-การประเมินผล (classification_report, confusion_matrix): ใช้สำหรับประเมินประสิทธิภาพของโมเดล
-การปรับแต่งข้อมูล (transforms จาก torchvision): ใช้สำหรับเตรียมข้อมูลภาพก่อนใช้งาน

-ที่มาของปัญหา: ในปัจจุบันมีรีวิวจำนวนมากเกี่ยวกับภาพยนตร์จากแหล่งข้อมูลต่างๆ เช่น IMDb, Rotten Tomatoes และเว็บไซต์อื่นๆ ซึ่งผู้ใช้ทั่วไปอาจไม่มีเวลาหรือความสามารถในการอ่านรีวิวทั้งหมดเพื่อสรุปประเภทของภาพยนตร์ได้อย่างแม่นยำ นอกจากนี้ การใช้ภาษาที่แตกต่างกันของผู้รีวิวอาจทำให้การจำแนกประเภทของภาพยนตร์เป็นเรื่องยาก ดังนั้น เพื่อช่วยลดภาระในการอ่านและทำความเข้าใจรีวิว เราจึงต้องใช้ปัญญาประดิษฐ์ (AI) และเทคนิค Machine Learning มาช่วยในการแยกประเภทของภาพยนตร์จากรีวิวโดยอัตโนมัติ ซึ่งจะช่วยให้ผู้ใช้สามารถทราบแนวหนังที่ต้องการได้อย่างรวดเร็วและแม่นยำ ที่มาของข้อมูล:รวบรวมข้อมูลจาก https://bdi.or.th/big-data-101/tf-idf-1/ ,https://ph02.tci-thaijo.org/index.php/TJOR/article/download/243329/165596,https://www.softnix.co.th/2019/05/28/tf-idf-%E0%B8%97%E0%B8%B3%E0%B8%87%E0%B8%B2%E0%B8%99%E0%B8%A2%E0%B8%B1%E0%B8%87%E0%B9%84%E0%B8%87/ โดยใช้ Perplexity ในรวบรวมข้อมูล การTrain Models ใช้ข้อมูลจาก https://www.kaggle.com/ โดยใช้ การเตรียมข้อมูล (Data Preparation):
เก็บรวบรวมข้อมูล: ใช้ชุดข้อมูลที่มีข้อความและป้ายกำกับที่สอดคล้องกัน เช่น ข้อความรีวิวสินค้าพร้อมกับคะแนนความพึงพอใจ
ทำความสะอาดข้อมูล: ลบข้อมูลที่ไม่จำเป็น เช่น เครื่องหมายวรรคตอน ตัวเลข หรือสัญลักษณ์พิเศษ และแปลงข้อความเป็นตัวพิมพ์เล็กทั้งหมดเพื่อความสม่ำเสมอ
การแปลงข้อความเป็นเวกเตอร์ด้วย TF-IDF (Feature Extraction):
TF-IDF (Term Frequency-Inverse Document Frequency): เป็นเทคนิคที่ใช้แปลงข้อความเป็นเวกเตอร์ของตัวเลข โดยให้ค่าน้ำหนักกับคำที่มีความสำคัญในเอกสาร แต่ปรากฏไม่บ่อยในชุดข้อมูลทั้งหมด การผสมผสานระหว่าง TF-IDF และ Logistic Regression เป็นแนวทางที่มีประสิทธิภาพในการจำแนกประเภทข้อความ เนื่องจาก TF-IDF ช่วยเน้นคำที่มีความสำคัญ ในขณะที่ Logistic Regression เป็นโมเดลที่เรียบง่ายแต่ทรงพลังในการจำแนกข้อมูล
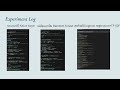
ที่มา: ในปัจจุุบัน มีผู้ใช้งาน Reddit & Twitter จำนวนมาก ซึ่งบ่อยครั้งเราไม่สามารถรู้ได้ว่าผู้ใช้งานคิดอย่างไรหรืออารมณ์ในขณะนั้นเป็นอย่างไรจาก comment หรือ tweet ซึ่งในบางโพสต์เช่น โพสต์ข่าว เป็นต้น เราอาจจะต้องการฟีดแบ็คของ user ว่าคิดเห็นอย่างไรกับข่าวที่โพสต์ การทำนายอารมณ์ของผู้ใช้งานนี้จึงสามารถช่วยให้รู้ได้ถึงอารมณ์ความรู้สึกของ user ซึ่งจะสามารถนำไปใช้ประโยชน์กับการโพสต์ข่าวได้อีกมากมายต่อไป
แหล่งข้อมูล: ทำการนำนายอารมณ์ของผู้ใช้งาน Reddit และ Twitter จาก comment หรือ tweet โดยใช้ฐานข้อมูล Twitter and Reddit Sentimental analysis Dataset ซึ่งมีจำนวนรวมทั้งหมด 200229 แถว 1 คอลัมป์ (negative medium positive)(-1 0 1)
การแก้ไขปัญหา: ใช้เทคนิคการทำ pre-processing data ก่อน เนื่องจากในฐานข้อมูลมี null อยู่ จากนั้นทำ databalancing, ทำการ cast text จาก uppercase to lowercase และทำการ tokenize text ให้กลายเป็น words เพื่อเพิ่มประสิทธิภาพการทำนาย จากนั้นเลือกใช้ CNN ในการสร้าง model

ที่มา
งานนี้อ้างอิงจาก senior project senior ที่กำลังดำเนินการทำอยู่ โดยมีสมาชิกร่วมทำ 3 คน ทั้งนี้จะนำเสนอ process ที่เกี่ยวข้องกับ ML เฉพาะในส่วนที่ตนเองทำเท่านั้น คือตรวจสอบ metrics precision recall mAP50 จาก hyperparameter ของ gridsearch12กรณี โดยจะยกตัวอย่างเฉพาะในชิ้นส่วนของโครงสร้างเฉพาะ Pier จากที่ทำไว้ทั้งหมดมี Pier Slab Girder ) -การใช้ข้อมูลรูปภาพที่ผ่าน dataclean จากกรมทางหลวงแล้ว (BMMS) มาจำแนกประเภท classification ความเสียหายที่เกิดขึ้นในโครงสร้างสะพานโดยหลักๆประกอบด้วย 1.Cracking 2.Spailing 3. SteelExposure 4.Erosion โดยนำข้อมูลรูปภาพเข้าสู่ roboflow เพื่อตั้ง dataset , label ประเภทความเสียดัง4ชนิดที่กล่าวไป และปรับ hyperparameter หลังจากนั้นใช้ roboflow แปลงข้อมูลรูปภาพให้อยู่ในรูปของ code ในเวอร์ชั่น yolo v.11 (ซึ่งเป็นอัลกอริทึมที่ใช้ตรวจจับความเสียหาย) แล้วนำ code สำเร็จรูปที่ได้มา run ใน colab ที่มี code สำเร็จรูปสำหรับการ training สำหรับ yolo v.11 มีการใช้ค่า epoch ,Learning rate , batch หรืออื่นๆรวมด้วย จากนั้นจึงแสดง result ประสิทธิภาพได้อยู่ในรูปของ %precision ,recall ,F-value หรือ confusion matrix ได้ออกมาสำเร็จรูป รวมถึงภาพตัวอย่างแสดง detection ที่ใช้กับตัว testing
วิธีการดำเนินงาน
- เตรียมฐานข้อมูลรูปภาพ BMMS ที่รวบรวมความเสียหายของโครงสร้างสะ ทั้งหมดที่ได้มาจากกรมทางหลวง
- เลือกใช้รูป BMMS ที่ผ่านจาก DATACLEAN มาใช้งาน
- การกำกับ/จัดตั้งค่า รูปภาพบน Roboflow (Classification,augmentation,adjustment training set valid set test set)
- การทำ Model Training ใน Colab ด้วย YoloV11 (detection,metric,loss function,confusionmatrix)
ที่มา
steam คือแหล่งจำหน่ายเกมอันดับต้นๆ ของโลก ซึ่งsteamจะมีการเก็บข้อมูลจำนวนผู้ใช้ที่ออนไลน์อย่างต่อเนื่องและเมื่อมีผู้ใช้งานสูงขึ้น steam จึงต้องเพิ่ม server เพื่อรองรับผู้ใช้งานให้สามารถใช้ steam ได้ และเมื่อมีผู้ใช้งานออนไลน์น้อยลงก็จะลดจำนวน server ที่จะเปิดใช้งาน การคาดการณ์จำนวนผู้ใช้งานจึงมีประโยชน์เพื่อใช้ควบคุมการเพิ่มลดจำนวน server
วิธีการ
- นำข้อมูลจากฐานข้อมูลที่เก็บไว้ในเว็บไซต์ SteamDB มาคัดข้อมูล
- เลือกใช้ Python
- ใช้ PyCharm Community ในการเขียนโค๊ด
- ใช้โมเดล Prophet ในการพัฒนา AI (Prophet คือ model ที่พัฒนาโดย Facebook)
- Model evaluation คือ mean square error และ mean absolute error
- ทำหน้า UI เพื่อให้ใช้งานได้ง่ายขึ้น
แหล่งที่มา
- https://steamdb.info/charts/
